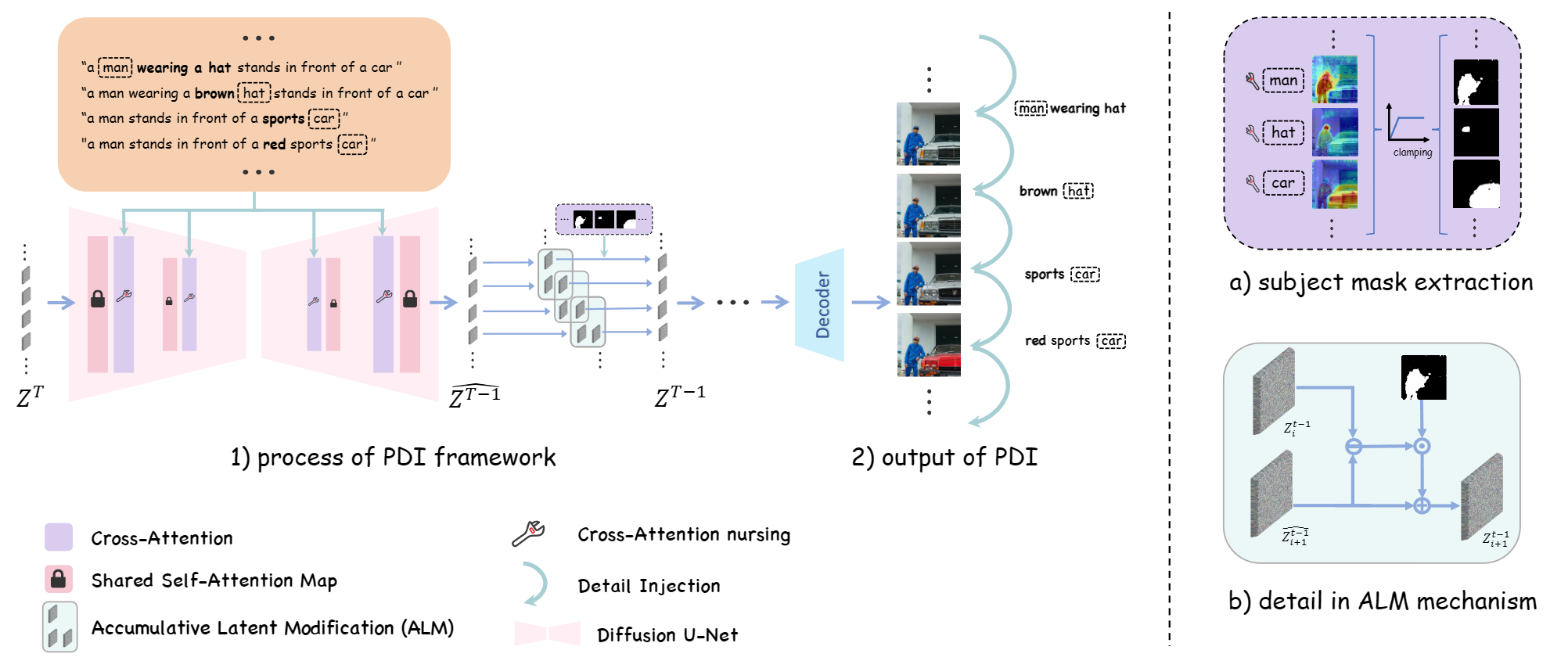
Recent advances in text-to-image (T2I) generation have led to impressive visual results. However, these models still face significant challenges when handling complex prompts—particularly those involving multiple subjects with distinct attributes. Inspired by the human drawing process, which first outlines the composition and then incrementally adds details, we propose Detail++, a training-free framework that introduces a novel Progressive Detail Injection (PDI) strategy to address this limitation. Specifically, we decompose a complex prompt into a sequence of simplified sub-prompts, guiding the generation process in stages. This staged generation leverages the inherent layout-controlling capacity of self-attention to first ensure global composition, followed by precise refinement. To achieve accurate binding between attributes and corresponding subjects, we exploit cross-attention mechanisms and further introduce a Centroid Alignment Loss at test time to reduce binding noise and enhance attribute consistency. Extensive experiments on T2I-CompBench and a newly constructed style composition benchmark demonstrate that Detail++ significantly outperforms existing methods, particularly in scenarios involving multiple objects and complex stylistic conditions.





Some results visualization. Here are some examples with complex prompt generated by our method. For each image pair, the left image is the result of baseline, and the left image is the result of our method. It can be easily found that our method can generate more accurate results with less semantic overflow and mismatched attributes.
@misc{chen2025detailtrainingfreeenhancertexttoimage,
title={Detail++: Training-Free Detail Enhancer for Text-to-Image Diffusion Models},
author={Lifeng Chen and Jiner Wang and Zihao Pan and Beier Zhu and Xiaofeng Yang and Chi Zhang},
year={2025},
eprint={2507.17853},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.17853},
}
 A comparison between our method and current state-of-the-art generative models.
The mainstream models often suffer from issues such as semantic overflow, complex attribute mismatching, and style blending. Even Flux, the leading generative model under
the DiT framework, struggles to overcome these challenges. In contrast, our method, Detail++, based on SDXL, achieves highly accurate
semantic binding in training-free way.
A comparison between our method and current state-of-the-art generative models.
The mainstream models often suffer from issues such as semantic overflow, complex attribute mismatching, and style blending. Even Flux, the leading generative model under
the DiT framework, struggles to overcome these challenges. In contrast, our method, Detail++, based on SDXL, achieves highly accurate
semantic binding in training-free way.